Default Hive¶
Prerequisites¶
Open Ports for Connections¶
For ports information, see Ports for Hive.
Collect Setup Information¶
JDBC URI or hostname and port of your Hive database
WebHDFS server and port
Metastore URI
If your Hive DB is deployed on Amazon S3, parameters for Query Log Ingestion (QLI) over S3:
AWS Access Key ID
AWS Access Key Secret
AWS Region
Log files to be excluded, if applicable
If using Apache Spark, parameters for QLI with Spark:
Spark Log Folder Amazon S3 Path
Spark Log File Name Prefix
Number of Log files in directory
Log4j Time Format
Log4j Conversion Pattern
With metastore on AWS Glue:
Access Key ID
Access Key Secret
AWS Region—Region name should appear as listed in AWS API Gateway Table.
Kerberos information, if applicable:
Hive Principal
Metastore Principal
Keytab: keytab access is supported. You will need to provide a valid keytab on the data source Settings page.
If using Apache Knox:
Documentation on the Knox WebHDFS URI, as well as how Knox routes gateways, topologies, and clusters using this URI can be found at the Knox book.
QLI Information¶
The default locations of Job History Logs on various platforms are listed below. Each of the folders should have sub-directories named YYYY/MM/DD (for example: 2016/02/24). Use Hue or Hadoop HDFS CLI to confirm that .jhist and .xml files are present in YYYY/MM/DD sub-directories (for example: 2016/02/24/00001/abc.jhist).
For CDH: /user/history/done
For MapR: /var/mapr/cluster/yarn/rm/staging/history/done
For AWS EMR: /tmp/hadoop-yarn/staging/history/done (WebHDFS port can be 9101)
For other stacks with YARN: /mr-history/done
HDP with Tez: /ats/done/
Network access from Alation to WebHDFS Server and port (default 50070 or 9870, config parameter
dfs.http.address)The default WebHDFS port depends on the Hadoop version and distribution. For Hadoop 2.x, the default WebHDFS port is 50070. For Hadoop 3.x, in some of the distributions, the default WebHDFS port may be 9870. For example, in the latest CDH distribution, the default WebHDFS port is 9870.
Hive QLI also supports reading the logs from a zip file that is stored on HDFS. The zip file is accessed using WebHDFS; the service account needs READ permissions on that file if you want to use the zipped log files for QLI. The zip file can be selected as the source for QLI when adding a Hive data source in Alation UI.
We provide an example of how to create the zip file. The following three lines of code download the logs created on 2016-02-09 from HDFS, zip them and upload the zipped file on HDFS at/tmp folder:
hadoop fs -get /user/history/done/2016/02/09 ./2016_02_09
zip -r 2016_02_09.zip 2016_02_09/
hadoop fs -put 2016_02_09.zip /tmp
Adding Hive Data Source on Default Framework¶
To add data sources, you need the Server Admin role in Alation.
To add a Hive data source on default framework,
Click the Sources icon on the main toolbar in Alation to open the Sources page.
On the Sources page, in the upper-right corner, click Add and select Data Source. This brings up the Add a Data Source wizard:

In the Add a Data Source Wizard, enter the following information for your Data Source:
Title
Other Data Source Admins you are automatically assigned as a Data Source Admin for the data source you are adding. However, you can add other users to manage the settings of this data source. Hover over Assign Data Source Admins section to reveal the Add button, and click it to add other admins.
Who is setting this up? - Select an option
Click Continue Setup to continue to the next configuration step:
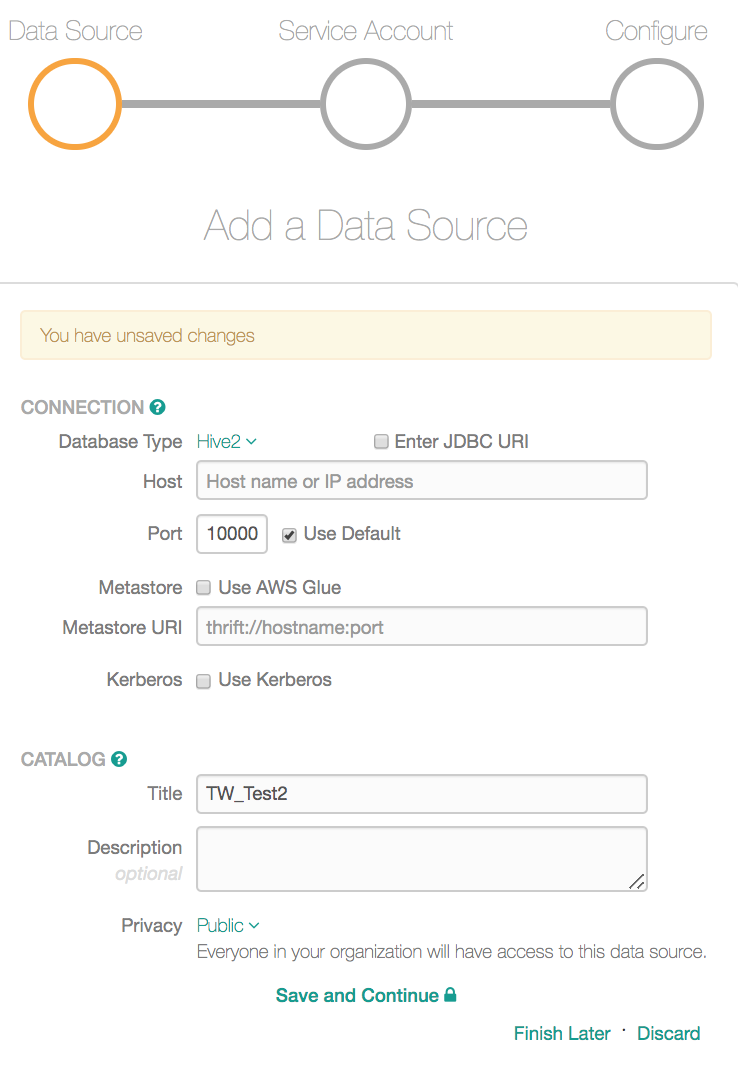
Under Connection, select the Database Type from the database list: Hive2.
Enter the network connection details. There are two options to do that for Hive:
Providing the hostname and port separately
Providing the host URI in the JDBC format.
You can choose the format by selecting or clearing the Enter JDBC URI checkbox on the upper right. By default, this checkbox is clear. Leave this checkbox clear to specify the hostname (or IP address) and the port number separately. Select Use Default checkbox for Port if you want to use the default port to connect.
If you want to use the JDBC format, select the Enter JDBC URI checkbox. Selecting it will change the input fields to accept the URI in the JDBC format: hive2://host:port/
You can use either an IP address or hostname for host. Example: hive2://10.11.21.108:1000/
Knox is supported for Metadata Extraction (MDE) and Query Log Ingestion (QLI): replace the Hive server URI with the Knox Server URI in the data source configuration.
In the Metastore URI field, specify the Hive Metastore URI.
If using Kerberos, select the Kerberos checkbox. This action will reveal the Kerberos-specific fields to be filled:
Hive Principal
Metastore Principal
If your Hive metastore is on AWS Glue, select the Use AWS Glue checkbox for Metastore. This action will reveal several additional settings in UI. You will need to provide:
Access Key ID Enter the access ID of the service account for AWS Glue.
Access Key Secret Enter the secret key of the service account for AWS Glue.
AWS Region The default value is us-east-1. If the value of the AWS Region is other than the default, enter values as mentioned under Region column at aws region documentation
Under Catalog, enter the Database Name, Description, and select the required Privacy setting (Public or Private).
Click Save and Continue to go to the next step that requires the service account information.
Note
You can also Continue with Errors and troubleshoot later.
Provide the Username and Password for the Service Account. For details on the required grants, see Database Service Account.
Click Save and Continue. This will take you to the next step that sets up Query Log Ingestion (QLI). You can:
skip this step and address the QLI settings later on the Settings page of this data source
choose to provide settings for QLI at this step if you are using the WebHDFS connection.
Note
With default Hive, if your Hive DB is deployed on EMR with QLI over Amazon S3, you have to skip this step because QLI for Hive on EMR on default framework can only be addressed on the Settings > Query Log Ingestion page.
If you decide to configure QLI at this step, provide the required parameters:
Under Import Query History, specify the Logs Source Type:
Directory
ZIP file
See QLI Information for details on the log paths.
If you use the Directory option, provide:
Logs Directory - note that the path will depend on your Hive platform and setup
If you use the ZIP File option, provide:
ZIP File Path
Provide information in fields:
WebHDFS Server
WebHDFS Port (or select Use Default)
Exclude Log Files (optional)
Click Verify and Finish Setup. Your Hive data source will be added and you will land on its Settings page. Proceed to specify the settings that apply to your Hive instance:
Keytab for Kerberos, if using keytabs
User impersonation
Knox URI
Hive driver (for connecting to CDH)
Note
If you connect to Cloudera, the default JDBC driver for Hive will fail during configuration. The JDBC driver cannot be changed until after the connection is established. To resolve this issue, ensure that you use the following driver: com.alation.drivers.hive.Hive2Driver.com.alation.drivers.hive.one.kerb_ssl_patched.1.1.1-kerberos-ssl-patched-1.1.1
Continue to Hive Data Source Settings