GCP Databricks¶
Applies from version 2021.3
Scope of Support¶
Automatic MDE and Profiling, file-based QLI, Popularity, Lineage, Compose
Delta tables are supported. Alation has the ability to extract Delta tables and supports Metadata Extraction, Profiling, and Compose. Users can write queries against Delta tables in Compose. Delta tables are represented as Table objects in the Alation Catalog.
Partitioned tables are supported
Query Log Ingestion is not supported.
Preliminaries¶
The following information and configuration is required to configure an GCP Databricks connection in Alation:
JDBC URI¶
Include the following components into the below mentioned URI:
Hostname
Databricks HTTP Path Prefix
Databricks Cluster ID
User Agent Entry - Alation recommends setting the user agent attribute as a parameter in JDBC URL because it will help you to identify the requests performed by Alation. This is useful for debugging problems caused by Alation or for logging purposes.
Note
The property
UseNativeQuery=0is required for custom query-based sampling and profiling. Without this property in the JDBC URI, custom query-based sampling or profiling will fail. If you are not using custom query-based sampling and profiling in your implementation of this data source type, you can omit this property from the JDBC URI string.Find more information in ANSI SQL-92 query support in JDBC in Azure Databricks documentation.
JDBC URI Pattern:
spark://<hostname>:443/default;transportMode=http;ssl=1;httpPath=<databricks_http_path_prefix>/<databricks_cluster_id>;AuthMech=3;UserAgentEntry=Alation/2021.3;UseNativeQuery=0;;
Example:
spark://4724910916864653.3.gcp.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/5678080404529670/1129-091234-pooh138;AuthMech=3;UserAgentEntry=Alation/2021.3;UseNativeQuery=0;
Service Account¶
A service account with privileges to access the Databricks cluster for Metadata Extraction and Profiling. Alation supports the following type of authentication:
Token-based authentication: For information on how to generate a unique token and use it for authentication, see this article.
Metadata Extraction¶
The service account requires access to the Databricks cluster. It must be able to access the tables and metadata to perform the extraction process.
Profiling/Sampling¶
The service account requires access to the Databricks cluster to perform Profiling/Sampling.
Steps in Alation¶
STEP 1: Add a New Datasource¶
Add a new Datasource on the Sources page.
Step 2: Set up the Connection¶
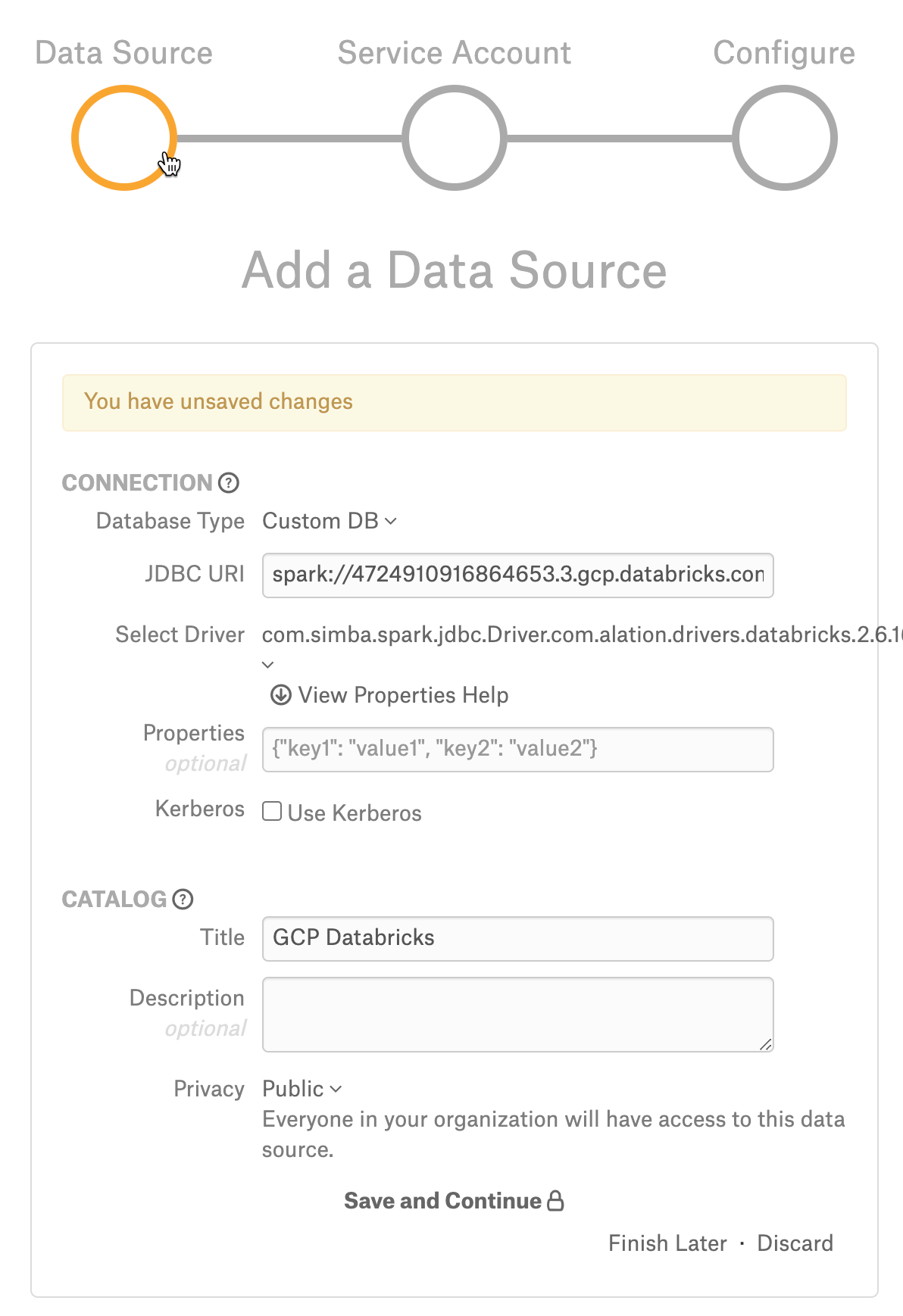
On the Add a Data Source screen of the wizard, specify:
Database Type: Custom DB
JDBC URI: URI in the required format. See JDBC URI.
Example:
spark://4724910916864653.3.gcp.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/5678080404529670/1129-091234-pooh138;AuthMech=3;UserAgentEntry=Alation/2021.3;Select Driver: select the Simba Spark JDBC driver for GCP Databricks from the Select Driver drop-down list. Refer to the appropriate version of Support Matrix for the driver version.
Click Save and Continue. The next wizard screen - Set Up a Service Account - will open.
Note
Do not select the Kerberos ‘Use Kerberos’ checkbox.
Step 3: Enter Service Account Credentials¶
Enter the token information in the Username and Password fields as follows:
Username: type the word token.
Password: enter the token string.
Step 4: Configure Your Data Source¶
Click Skip this Step. QLI for this type of data source is set up on the Settings > Query Log Ingestion tab and requires additional configuration on the Databricks side (see below).
After this step you are navigated to the Settings page of your data source.
Metadata Extraction¶
Configure and perform metadata extraction and verify the results:
In Settings > Custom Settings, set the Catalog Object Definition to Schema.Table:
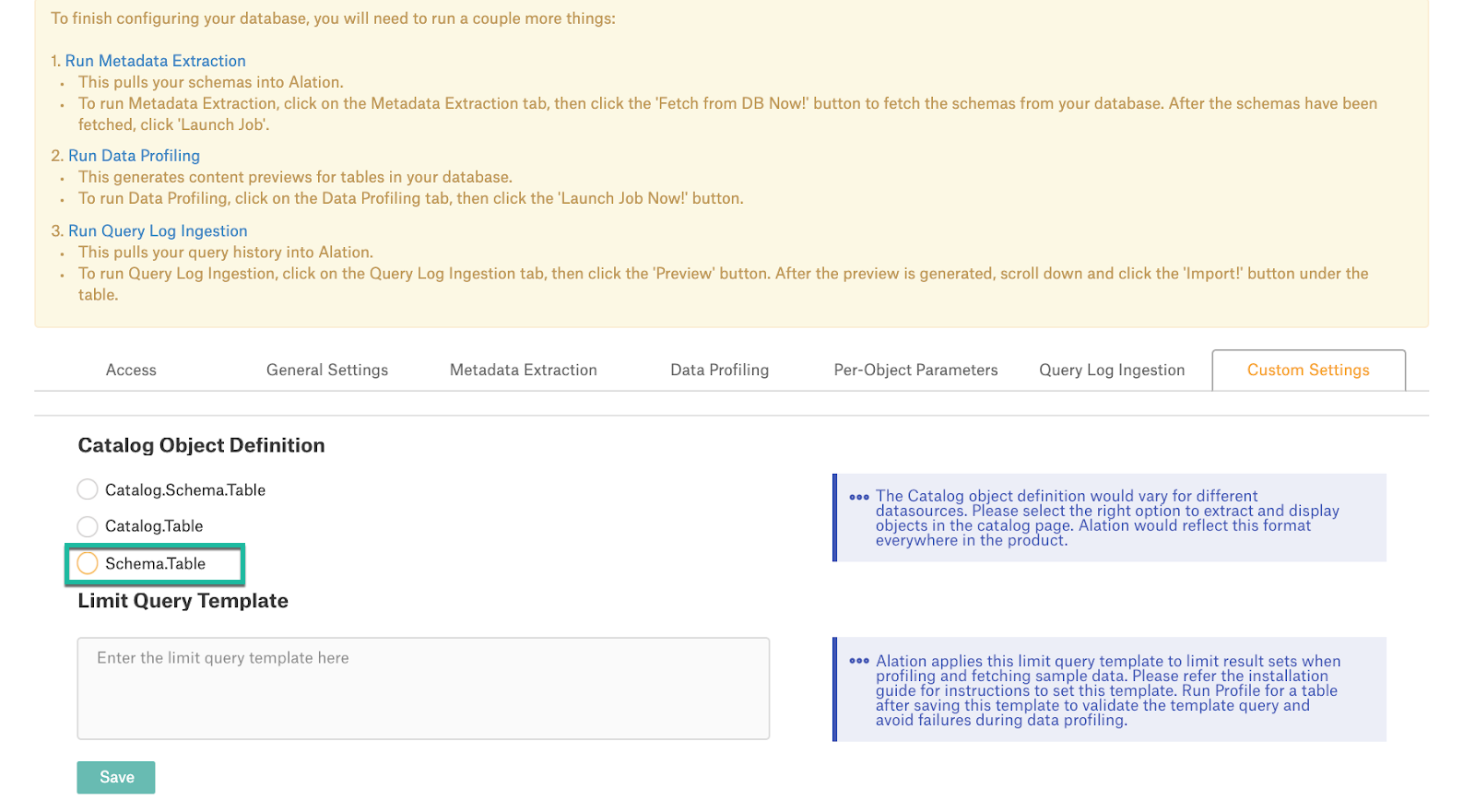
In Settings > Metadata Extraction, set up and perform MDE. Refer to Metadata Extraction.
For GCP Databricks, Alation supports automatic MDE, manual or scheduled. Custom query-based MDE is not supported for this type of data source.
Profiling¶
Configure and perform Sampling and Profiling :
Users can run a sample for an individual table on the Samples tab of the Table Catalog page or profile an individual column on the Overview tab of the Column page.
Automatic full and selective Profiling is supported.
Use the Per-Object Parameters in Settings tab to specify which objects to profile.
Note
Ensure that you clear the Skip Views checkbox of the respective schemas to perform the Profiling.
Important
To use custom query-based sampling and profiling, ensure that the JDBC URI includes the
UseNativeQuery=0property. If you enable dynamic profiling, then users should ensure that their individual connections also include this property.
Query Log Ingestion¶
Not supported.
Compose¶
Log into Compose:
Authenticate in Compose with your GCP Databricks credentials.
Use the Schema.Table format for writing queries.
Note
OAuth for Compose is not supported for Databricks on GCP.