Versions Prior to 3.9.0¶
Alation Cloud Service Applies to Alation Cloud Service instances of Alation
Customer Managed Applies to customer-managed instances of Alation
Configure metadata extraction on the Metadata Extraction tab of the settings. You can configure extraction to be full or incremental. Incremental extraction requires additional configuration in Amazon S3.
Note
Folders at the last level of a directory that have no name and are empty cannot be extracted.
Connector Settings¶
Metadata Extraction Configuration¶
Specify the metadata extraction configuration settings and click Save:
Note
When you run MDE, the Amazon S3 OCF connector obtains the list of inventory files from the latest manifest.json file for the respective bucket. Manifest files are available at the following location in the destination bucket:
destination-prefix/source-bucket/config-ID/YYYY-MM-DDTHH-MMZ/manifest.json
For more information about manifest.json file, refer to Inventory manifest in AWS documentation.
Parameter |
Description |
|---|---|
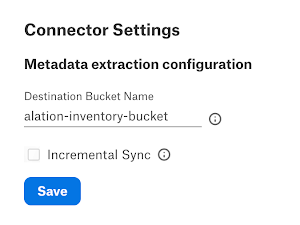
Destination Bucket Name |
Provide the name of the destination bucket that hosts the inventory reports. Note The wait time is 24 to 48 hours for the first inventory report to be generated once the inventory function is set. If you run MDE before the inventory report generation then Alation will not extract any data. |
Incremental Sync |
Select this checkbox to extract only the new object additions or deletions. However, the first extraction is always a full metadata extraction. Important Ensure that you have performed the necessary configurations in S3 before enabling the Incremental Sync checkbox. The required S3 configuration can be done in two ways: manually or using a Terraform script. For details, refer Set Up Incremental MDE |
Schema Extraction Configuration¶
A schema extraction job will extract and catalog column headers found in semi-structured file formats, such as Parquet, CSV, PSV, and TSV. Note that schema extraction may be a time-intensive operation as it involves reading individual files.
Under Schema extraction configuration, specify the schema extraction configuration settings and click Save.
Parameter |
Description |
|---|---|
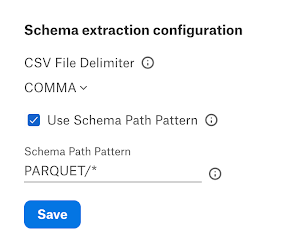
CSV File Delimiter |
Select the CSV file delimiter within all the CSV files in the file system source from the dropdown. The default delimiter value is COMMA. |
Use Schema Path Pattern |
Enable the Use Schema Path Pattern checkbox to extract schema (columns/headers) for folders matching the pattern. When the Use Schema Path Pattern is enabled, the Schema Extraction job will not match any individual CSV/PSV/TSV/ Parquet files. It will only match the files which are valid for given schema path pattern. |
Schema Path Pattern |
Provide the Schema Path Pattern for schema extraction. For more information, refer to Schema Path Pattern. |
Selective Extraction¶
On the Metadata Extraction tab, you can select the buckets to include or exclude from extraction. Enable the Selective Extraction toggle if you want only a subset of buckets to be extracted.
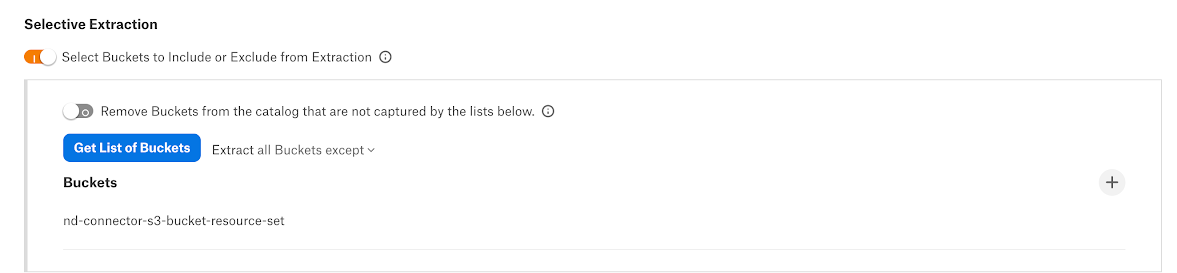
To extract only specific buckets:
Click Get List of Buckets to first fetch the list of buckets. The status of this action will be logged in the Extraction Job Status table at the bottom of the Metadata Extraction tab.
When bucket synchronization is complete, a drop-down list with the available buckets will become enabled.
Select one or more buckets as required.
Check if you are using the correct filter option. Available filter options are described below:
Filter Option
Description
Extract all Buckets except
Extract metadata from all buckets except from the selected buckets.
Extract only these Buckets
Extract metadata only from the selected buckets.
Click Run Extraction Now to extract metadata. The status of the extraction action is also logged in the Job History table at the bottom of the page.
Run Extraction¶
Extraction Scheduler¶
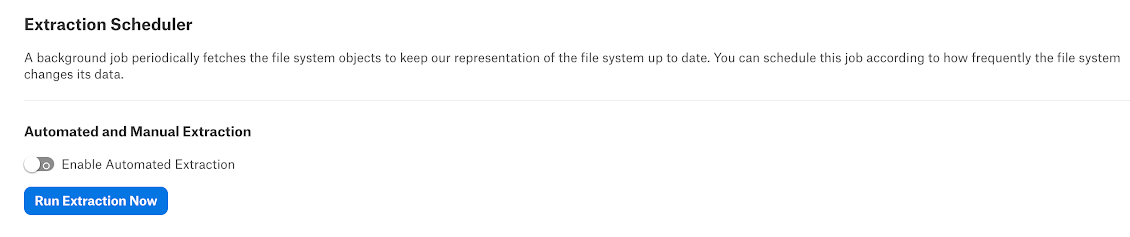
If you want to automatically update the metadata extracted into the catalog, under Automated and Manual Extraction, turn on the Enable Automated Extraction switch and select the day and time when metadata must be extracted. The metadata extraction will be automatically scheduled to run on the selected schedule.
Important
When you configure incremental MDE, we recommend scheduling it to run on a daily basis. If you run the MDE job weekly or bi-weekly, incremental extraction will need to process the events for the last seven or 15 days, which is likely to slow it down.
Do not use the incremental sync if the MDE schedule is set to run weekly or bi-weekly.
Schema Extraction¶
After you have extracted the bucket metadata, you can additionally extract the schema information for CSV, PSV, TSV and Parquet files. Schema extraction enables file sampling.
Schema extraction uses the configuration described in Schema Extraction Configuration.
To perform schema extraction:
Ensure that you have configured schema extraction under the Schema extraction configuration section. If your data files are in the CSV format, ensure that you’ve selected the correct delimiter in the CSV File Delimiter field.
Click Run Schema Extraction to extract the schema (column headers) for each Parquet, PSV, TSV, or CSV files.