Prerequisites¶
Alation Cloud Service Applies to Alation Cloud Service instances of Alation
Customer Managed Applies to customer-managed instances of Alation
Prior to configuring and using the connector in Alation, you must perform the following steps:
Note
We’ll refer to the buckets to be cataloged as the source buckets and to the inventory bucket that stores the inventory reports as the inventory or destination bucket.
Configure the Inventory — Create the destination bucket to store the inventory reports.
Additionally, consider the recommendations in Scale Amazon S3 OCF Connector when configuring the inventory.
Configure Required Permissions — Give Alation access and collect the authentication information. Set permissions required for Metadata Extraction.
Configure Server-Side Encryption (optional) — Perform additional configuration if you are using an encryption type other than SSE-S3 (default).
Set Up Incremental MDE (optional) — Configure incremental MDE using a Lambda function. Each consecutive incremental MDE job will only extract new metadata and metadata updates, but not all accessible metadata.
Important
Incremental extraction is a resource consuming event. Review the prerequisites listed in Set Up Incremental MDE and the additional cost you may incur within your AWS account before you proceed, if you have not already done so. Alation recommends using this feature only when the volume of incremental changes is less compared to the total number of objects extracted. Example: 10K incremental changes over 5 million objects.
Configure the Inventory¶
Metadata extraction from an Amazon S3 file system source uses inventory reports of Amazon S3 buckets. The inventory reports are stored in a dedicated S3 bucket used for the inventory only. During metadata extraction, Alation will extract the inventory reports stored in the inventory bucket and stream the metadata to the catalog.
Note
To have metadata from the inventory extracted properly into Alation, you’ll need to put the inventory into an inventory bucket.
Inventories from many source buckets can be delivered to a single destination bucket.
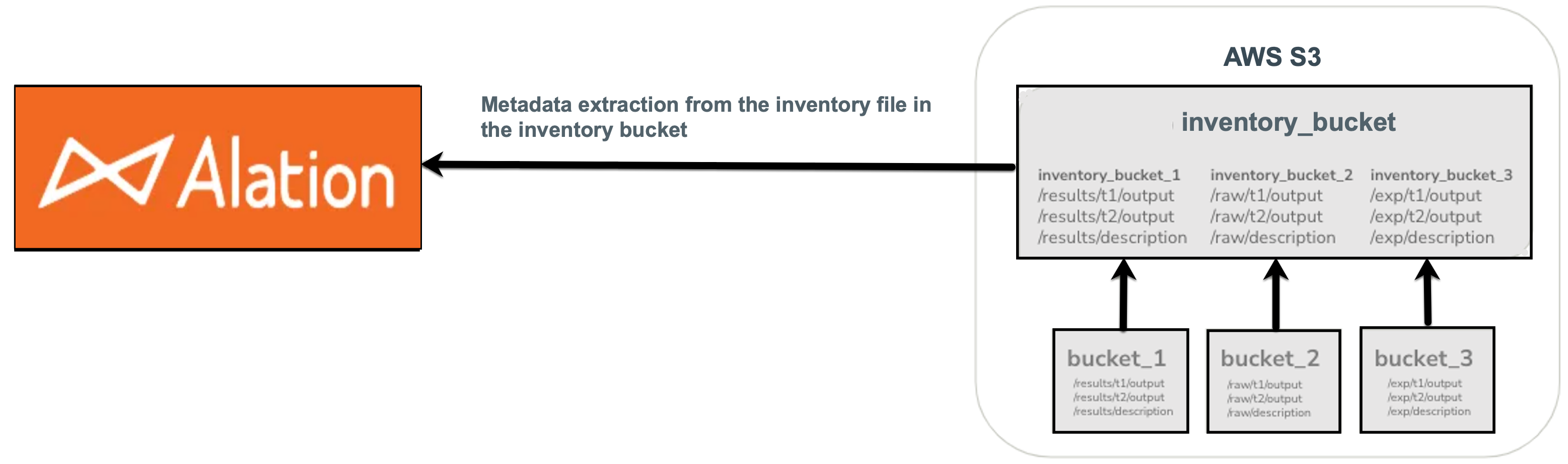
The inventory or destination bucket for storing inventory reports can either be created manually using the steps provided below or using a Terraform script.
Configure the Inventory Manually¶
You require the privileges of an AWS administrator to create new buckets and configure inventory for buckets with data. Following are the steps involved in configuring the inventory manually:
Note
It may take AWS up to 48 hours to deliver the first report into the destination bucket. You will need to ensure that all the inventory reports that you want ingested into Alation have been delivered to your destination bucket before you are able to extract the metadata.
Create an S3 Bucket to Store Inventory Reports¶
To create a bucket:
Create a dedicated bucket to be used as the destination bucket for the S3 bucket inventory reports that you want to ingest into Alation. Create this bucket in the same AWS region as your source buckets. The destination bucket should not be used for any other purpose or storing any other content. Alation expects that the destination bucket only stores the inventory reports.
Example:
alation-destination-bucketCreate a folder called
inventoryor any<custom-inventory-folder-name>inside the inventory or destination bucket.
Configure the S3 Inventory¶
Important
The S3 inventory must be configured for every source bucket that you want ingested into the catalog.
To configure the inventory:
Follow the steps in Configuring inventory using the S3 console to configure the S3 inventory.
Under Report details, set Destination to your destination bucket with the inventory folder path in the format
s3://<Destination_Bucket_Name>/inventoryors3://<Destination_Bucket_Name>/<custom-inventory-path>.Note
Make sure there is no trailing slash
/symbol at the end of the path.Set Frequency to Daily or Weekly. Frequency must match the metadata extraction schedule you will set in Alation.
Set Output Format as CSV.
Set Status as Enable.
Optionally, populate additional fields:
Size
Last modified
It may take AWS up to 48 hours to deliver the first report into the destination bucket. Before extracting the metadata, ensure that all the inventory reports that you want ingested into Alation have been delivered to your destination bucket.
Configure Inventory with a Terraform Script¶
Alation can provide a Terraform script that can be used to configure the necessary AWS resources such as a destination bucket for inventory reports and a Lambda function for incremental extraction. Find the information about it in Use Terraform to Set Up Inventory and Incremental MDE.
Configure Required Permissions¶
Configure permissions for:
Authentication
Metadata Extraction
Configure Permissions for Authentication¶
The OCF connector for Amazon S3 supports several authentication methods:
Basic Authentication¶
Basic authentication requires an AWS IAM user and the access key ID and secret access key for this user.
Create an AWS IAM User¶
To use basic authentication, create an AWS IAM user account for Alation and save the values of the access key and secret access key to a secure location.
Grant the IAM user the required permissions (see Permissions for IAM User Account).
Permissions for IAM User Account¶
The user account requires read-only access to the source and destination buckets:
For more information, see Grant Permissions for Metadata Extraction.
Below, find an example of an IAM policy allowing the required actions for all S3 buckets in an account. You can adjust this example to include only the necessary resources: the destination and source buckets. Refer to Allowing an IAM user access to one of your buckets in AWS documentation for more information.
Example:
{
"Version": "2012-10-17",
"Statement":
[
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": "*"
}
]
}
STS Authentication with an IAM User¶
STS authentication with an IAM user requires an IAM user and role.
Note
File sampling is not supported with STS authentication.
Create an IAM User¶
To configure STS authentication with an IAM user:
Create an AWS IAM role.
To this role, assign a policy with the access to the following:
Read-only access to the destination bucket.
Read-only access to the source buckets.
Note
If you don’t intend to perform schema extraction or incremental MDE, you can provide read-only access to the destination bucket only.
Create a user in AWS IAM with the following policy:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", }, "Action": "sts:AssumeRole", "Resource": "{ARN_OF_THE_ROLE}" ] }
Note down the ARN of the user.
Open the properties of the role you created in step 2 and go to the Trust Relationship section. Add trusted entities as shown below:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "{ARN_OF_THE_USER}" }, "Action": "sts:AssumeRole" } ] }
STS Authentication with an AWS IAM Role¶
STS authentication with an AWS IAM role uses an instance profile that assumes a role allowing access to Amazon resources. This authentication method works for authenticating across AWS accounts.
Note
STS Authentication with an AWS IAM role is available with connector version 3.8.5.6552 or newer.
To configure STS authentication with an AWS IAM role, use the steps in Configure Authentication via AWS STS and an IAM Role. To provide access to the data source via an IAM role, use the permissions information in Permissions for IAM User Account.
Grant Permissions for Metadata Extraction¶
Grant permissions for:
Metadata Extraction (Without Incremental Sync)
Incremental Sync, Column or Schema Extraction, and Sampling
For Metadata Extraction (Without Incremental Sync)¶
You must have listBucket and getObject IAM permissions to inventory or destination bucket.
listBucket- Required to list the inventory files and manifest files from the inventory or destination bucket.getObject- Required to read the inventory CSV files from the inventory or destination bucket.{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": [ "arn:aws:s3:::{YOUR_DESTINATION_BUCKET}", ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "s3:GetObject", "Resource": [ "arn:aws:s3:::{YOUR_DESTINATION_BUCKET}/*", ] } ] }
For Incremental Sync, Column or Schema Extraction, and Sampling¶
You must have listBucket and getObject IAM permissions to inventory or destination bucket and all source buckets.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": [ "arn:aws:s3:::{YOUR_SOURCE_BUCKET_1}", "arn:aws:s3:::{YOUR_SOURCE_BUCKET_2}", "arn:aws:s3:::{YOUR_SOURCE_BUCKET_N}", "arn:aws:s3:::{YOUR_DESTINATION_BUCKET}", ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "s3:GetObject", "Resource": [ "arn:aws:s3:::{YOUR_SOURCE_BUCKET_1}/*" "arn:aws:s3:::{YOUR_SOURCE_BUCKET_2}/*" "arn:aws:s3:::{YOUR_SOURCE_BUCKET_N}/*" "arn:aws:s3:::{YOUR_DESTINATION_BUCKET}/*", ] } ] }
For Incremental Sync:
listBucket- Deletes the parent folder if all the child folders are deleted.
getObject- Allows usingdoesObjectExistwhile deleting the directory.
For Schema Extraction and Sampling:
listBucket- Retrieves columns on source buckets for CData Parquet driver.
getObject- Reads actual objects to find its columns for CData driver.
Scale the Amazon S3 Connector¶
You can use various approaches to scale the Amazon S3 OCF connector while setting up the inventory and later configuring the connector in Alation. For example, you can create prefixes. Find more information in Scale Amazon S3 OCF Connector.
Configure Server-Side Encryption¶
Alation supports the SSE-S3 (default) and SSE-KMS encryption types:
SSE-S3 does not require any additional configuration.
SSE-KMS requires additional permission configuration. See Configure Server-Side Encryption.
Set Up Incremental MDE¶
If you choose to enable incremental sync, you must configure incremental sync in Amazon S3. For more information, Set Up Incremental MDE for details.